
La transformation est tirée, et facilitée, par la profusion de données disponibles, sous une diversité de formats (structurées, non-structurées, textes, images, sons…) et de supports. D’après IDC, le volume global de données créées et stockées atteindra 179,6 zettabytes en 2025, contre 64,2 zettabytes en 2020, soit une croissance annuelle moyenne de 23 %. Les données créées dans le cloud pèseront 43 zettabytes en 2025 (soit 24 % du total), contre 9 zettabytes en 2020 (14 % du total). Rappelons qu’un seul zettabyte pourrait stocker le contenu de 180 millions de bibliothèques contenant chacune 25 millions d’ouvrages !
Ainsi, le volume global des informations créées et stockées au cours des cinq prochaines années sera plus important que tous ceux créés depuis l’invention du stockage numérique, assure IDC. Certes, seulement 2 % de ces données ont survécu en 2021, le reste était éphémère, c’est-à-dire créé pour une action particulière ou écrasé par de nouvelles données. Mais la barre des 100 zettaoctets de données (soit l’équivalent de 22 milliards de films en qualité 4K) créées sera franchie en 2023.
L’explosion des volumes de données est due en grande partie à l’utilisation croissante de l’analytique, à la prolifération des appareils IoT et aux initiatives de migration vers le cloud, selon une étude IDC-Seagate. La quantité de nouvelles données créées chaque année augmente à un taux de croissance annuel ddessus % pour la période 2015‑2025.
Environ 30 % des données stockées résident dans des centres de données internes, 20 % dans des centres de données tiers, 19 % dans des centres de données en périphérie ou à des emplacements à distance, 22 % dans des dépôts cloud et 9 % à d’autres emplacements. Cette répartition ne changera pas radicalement au cours des deux prochaines années, ce qui signifie que les environnements de stockage des entreprises resteront dispersés et complexes à moyen terme.
Les analystes avancent trois raisons pour expliquer le maintien de taux de croissance élevés des volumes de données : d’abord, le fait qu’elles sont cruciales pour les entreprises qui doivent garantir leur résilience et capitaliser dessus pour s’adapter aux évolutions de leur environnement. Y compris les anciennes données… Ensuite, les organisations s’appuient sur les données pour leur transformation digitale, découvrir de nouvelles opportunités et développer de nouvelles offres, par exemple avec les objets connectés ou l’usage intensif de solutions analytiques. Enfin, les données servent à maintenir les liens avec les clients, les salariés, les partenaires et toutes les parties prenantes des écosystèmes.
L’explosion des volumes de données est due en grande partie à l’utilisation croissante de technologies analytiques, à la prolifération des appareils IoT et aux initiatives de migration vers le cloud. Les entreprises estiment, dans leur grande majorité (près de sept sur dix), que ce mode d’organisation du système d’information est important pour réussir la transformation digitale. Parce qu’il est un facilitateur du digital, il fait gagner en temps, flexibilité, scalabilité et réactivité. Pour Gartner, le cloud pèse 14 %, en moyenne, des budgets IT (contre 10 % en 2019 et 8 % en 2018) et le marché mondial progressera de 15 % par an à l’horizon 2024.
Tous ces flux de données ont quatre caractéristiques : ils augmentent de façon exponentielle, ils sont de plus en plus dépendants les uns des autres, ils circulent selon des modes multi-canal et multi-formats, le poids des informations non structurées devient dominant.
Mais seulement environ 30,5 % des données dont leur entreprise dispose sont mises à profit. Les cinq principaux défis à relever pour exploiter le potentiel des données collectées sont les suivants :
- Rendre les données collectées utilisables.
- Gérer le stockage des données collectées.
- S’assurer que les données nécessaires sont collectées.
- Garantir la sécurité des données collectées.
- Rendre accessibles les différents silos de données collectées.
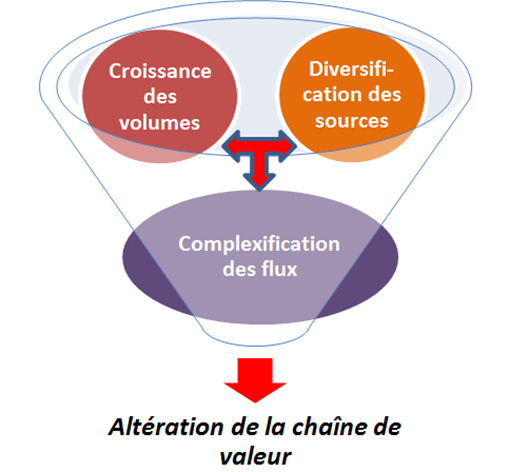
Le cycle de vie de la donnée, lorsqu’elle se transforme en information, en connaissance, puis en savoir, est soumis à plusieurs types de risques de non-qualité qui doivent être maîtrisés pour ne pas altérer la chaîne de valeur. Certes, il existe de nombreux outils dédiés à la qualité des données et dont les fonctionnalités concernent essentiellement la mesure de qualité, le formatage, le contrôle d’intégrité, l’identification des liens croisés, le monitoring par rapport aux règles métiers, la gestion des métadonnées et l’enrichissement. Si l’on synthétise les zones de risques liés à la non-qualité des données (voir tableau), on s’aperçoit que les faiblesses sont présentes tout au long du cycle de vie de l’information et de sa transformation. On assiste en effet à la conjonction d’au moins quatre types de risques, qu’il convient de maîtriser :
– les risques liés à la collecte des données, avec la diversification des sources de collecte et la conjonction d’informations structurées et non structurées,
– les risques liés à la croissance des volumes, dont les multiples études sur le big data montre que la tendance s’accélère,
– les risques liés à la complexification des flux, dès lors que se conjuguent des volumes importants de données et de multiples sources de collecte,
– les risques liés à l’altération de la chaîne de valeur, dès lors que les trois autres types de risques ne sont pas maîtrisés.
Face aux risques de non-qualité des données, plusieurs leviers d’action peuvent être actionnés : optimiser les modes de collecte des données, travailler sur la cohérence des informations, cartographier les flux et leurs impacts croisés, et analyser la valeur de l’information. Comment améliorer la qualité des données ? Tout d’abord, il faut mettre en relation les créateurs de donnés avec leurs « consommateurs », en partant du principe que la qualité de la donnée est fixée lors de sa création, mais qu’on ne juge celle-ci que lorsqu’elle est consommée. Faire travailler ensemble les créateurs et les consommateurs permet, en principe, d’identifier les sources de non-qualité, surtout si le créateur d’une donnée sait comment elle est utilisée.
Ensuite, il est pertinent de se focaliser sur la qualité des nouvelles données produites, de manière à améliorer durablement le processus, et non pas sur le stock existant, alors qu’il est tentant de vouloir tout corriger. Enfin, il est utile de confier la responsabilité de la qualité des données aux managers opérationnels et pas uniquement aux DSI, à charge pour eux de tout régler… Ce qui, généralement, conduit à des échecs, faute de temps, d’investissement… et de motivation.